『正文』
ˇ
大家好,我是乌克兰剑圣。 本期策略我们在Tbquant里手搓一个机器学习策略,我会以最浅显易懂的方式讲解手搓过程,策略代码800+且有完整注释。本策略是一个基于**K近邻(KNN)机器学习算法**的多因子突破交易系统,通过分析历史相似市场环境来预测当前突破信号的有效性。完整流程如下:
```┌─────────────────────────────────────────────┐│ Step 1: 提取当前K线的7个特征 ││ 趋势+动量+波动+成交量+BOLL+反转 │└─────────────────────────────────────────────┘ ↓┌─────────────────────────────────────────────┐│ Step 2: 样本标注(自动学习) ││ 用未来5期收益率标注历史样本 │└─────────────────────────────────────────────┘ ↓┌─────────────────────────────────────────────┐│ Step 3: KNN搜索(遍历500根历史K线) ││ 计算加权欧氏距离,找Top-5邻居 │└─────────────────────────────────────────────┘ ↓┌─────────────────────────────────────────────┐│ Step 4: 加权投票预测 ││ 距离倒数加权,输出预测信号 │└─────────────────────────────────────────────┘ ↓┌─────────────────────────────────────────────┐│ Step 5: 双重确认进场 ││ BOLL突破 + ML置信度≥65% │└─────────────────────────────────────────────┘ ↓┌─────────────────────────────────────────────┐│ Step 6: 动态止损管理 ││ 止损系数1.0→0.5递减 │└─────────────────────────────────────────────┘ ↓┌─────────────────────────────────────────────┐│ Step 7: 执行交易决策 ││ 进场/持仓/止损/观望 │└─────────────────────────────────────────────┘```Step 1: 提取当前K线的7个特征
计算当前K线的7个指标值,为KNN算法提供"市场指纹"。
// 均线系统MAFast = Average(Close, 10); // 10周期快线MASlow = Average(Close, 30); // 30周期慢线TrendStrength = Abs(MAFast - MASlow) / Close;// ADX(平均趋向指数)ATR = AvgTrueRange(14);PDI = Average(Max(High - High[1], 0), 14) / ATR * 100;MDI = Average(Max(Low[1] - Low, 0), 14) / ATR * 100;DX = IIF((PDI + MDI) != 0, Abs(PDI - MDI) / (PDI + MDI) * 100, 0);ADXValue = Average(DX, 6);// 动量指标ROC = (Close - Close[5]) / Close[5] * 100;RSIValue = RSI(14);MACD = XAverage(Close, 12) - XAverage(Close, 26);// 布林带BollMid = Average(Close, 20);BollStd = StdDev(Close, 20);BollUpper = BollMid + 2 * BollStd;BollLower = BollMid - 2 * BollStd;BollWidth = (BollUpper - BollLower) / BollMid;BollPosition = (Close - BollLower) / (BollUpper - BollLower);// 成交量VolumeMA = Average(Volume, 20);VolumeRatio = Volume / VolumeMA;...然后合成7个特征,:
if (MAFast > MASlow) { Feature1 = TrendStrength * (ADXValue / 100); } else { Feature1 = -TrendStrength * (ADXValue / 100); }Feature2 = ROC * 0.5 + (RSIValue - 50) * 0.5 + (MACD / Close * 100) * 0.3;Feature3 = VolatilityRatio * 100;Feature4 = VolumeRatio + OBVTrend * 0.1;Feature5 = BollPosition;Feature6 = IIF(BollWidth != 0, 1.0 / (BollWidth * 100), 10);Feature7 = BollExtreme + RSIExtreme + RSIDivergence + KDJExtreme;Feature7 = Min(Feature7, 1.0);当前特征值示例
```Feature1 = 0.6 (趋势向上,ADX中等)Feature2 = 0.7 (动量偏强)Feature3 = 0.5 (波动率正常)Feature4 = 0.8 (成交量放大)Feature5 = 0.4 (BOLL中下位置)Feature6 = 0.6 (BOLL收缩)Feature7 = 0.3 (弱反转信号)→ 当前特征向量 = [0.6, 0.7, 0.5, 0.8, 0.4, 0.6, 0.3]```归一化处理
Feature1_Max = Highest(Feature1, 500); Feature1_Min = Lowest(Feature1, 500); if ((Feature1_Max - Feature1_Min) != 0) { NormFeature1 = (Feature1 - Feature1_Min) / (Feature1_Max - Feature1_Min);} else { NormFeature1 = 0.5; }归一化示例
```Feature1原始值 = 0.35Feature1_Max = 0.8Feature1_Min = -0.6NormFeature1 = (0.35 - (-0.6)) / (0.8 - (-0.6)) = 0.95 / 1.4 = 0.679同样处理其他6个特征:NormFeature2 = 0.645NormFeature3 = 0.420NormFeature4 = 0.675NormFeature5 = 0.850NormFeature6 = 0.450NormFeature7 = 0.150→ 归一化特征向量 = [0.679, 0.645, 0.420, 0.675, 0.850, 0.450, 0.150]``` Step 2: 样本标注(自动学习)
为历史每根K线自动标注"标准答案",用于KNN训练,逻辑如下:
FutureReturn = (Close[CurrentBar] - Close[CurrentBar - 5]) / Close[CurrentBar - 5] * 100;if (FutureReturn > 1.0) { TradeLabel = 1; } else if (FutureReturn < -1.0) { TradeLabel = -1; } else { TradeLabel = 0; }标注结果示例
| K线时刻 | 当前收盘 | 5期后收盘 | 收益率 | 标签 | 是否使用 ||---------|---------|----------|--------|------|---------|| T=100 | 3000 | 3045 | +1.5% | **+1** (看涨) | ✓ || T=101 | 3010 | 3005 | -0.17% | **0** (震荡) | ✗ || T=102 | 3020 | 2985 | -1.16% | **-1** (看跌) | ✓ || T=103 | 3015 | 3030 | +0.5% | **0** (震荡) | ✗ || T=104 | 3025 | 3065 | +1.32% | **+1** (看涨) | ✓ |Step 3: KNN搜索(遍历500根历史K线)
这是在计算**当前K线**与**每个历史K线**之间的"相似度"。
计算欧氏距离
Distance = Sqrt( Power(NormFeature1 - HistFeature1, 2) * TrendWeight + Power(NormFeature2 - HistFeature2, 2) * MomentumWeight + Power(NormFeature3 - HistFeature3, 2) * VolatilityWeight + Power(NormFeature4 - HistFeature4, 2) * VolumeWeight + Power(NormFeature5 - HistFeature5, 2) * PatternWeight);想象你在**7维空间**中找最相似的K线:
1. 每个K线是7维空间中的一个点
当前K线坐标:点A = (0.6, 0.7, 0.5, 0.8, 0.4, 0.6, 0.3) ↓ ↓ ↓ ↓ ↓ ↓ ↓ 趋势 动量 波动 成交量 BOLL BOLL 反转 位置 收缩 信号历史K线坐标:点B = (0.5, 0.8, 0.4, 0.7, 0.5, 0.5, 0.4)2. 计算每个维度的差异
趋势差异² = (0.6 - 0.5)² = 0.01动量差异² = (0.7 - 0.8)² = 0.01波动差异² = (0.5 - 0.4)² = 0.01成交量差异² = (0.8 - 0.7)² = 0.01BOLL位置差异² = (0.4 - 0.5)² = 0.01BOLL收缩差异² = (0.6 - 0.5)² = 0.01反转信号差异² = (0.3 - 0.4)² = 0.013. 加权求和(重要特征权重更大)
加权距离² = 0.01×0.20 + 0.01×0.15 + 0.01×0.15 + 0.01×0.10 + 0.01×0.20 + 0.01×0.10 + 0.01×0.10 = 0.014. 开平方得到距离
Distance = Sqrt(0.01) = 0.1解读距离的含义:
-**Distance = 0**: 两根K线完全相同(几乎不可能)
-**Distance < 1.0**: 非常相似 ✅(可靠预测)
-**Distance = 1.0-3.0**: 中等相似 ⚠️(一般可靠)
-**Distance > 5.0**: 差异很大 ❌(不可靠预测)
具体计算案例:
假设当前K线与历史K线| 特征 | 当前值 | 历史值 | 差值 | 差值² | 权重 | 贡献 ||------|--------|--------|------|-------|------|------|| Feature1 | 0.679 | 0.650 | 0.029 | 0.000841 | 0.20 | 0.000168 || Feature2 | 0.645 | 0.680 | -0.035 | 0.001225 | 0.15 | 0.000184 || Feature3 | 0.420 | 0.450 | -0.030 | 0.000900 | 0.15 | 0.000135 || Feature4 | 0.675 | 0.620 | 0.055 | 0.003025 | 0.10 | 0.000303 || Feature5 | 0.850 | 0.820 | 0.030 | 0.000900 | 0.20 | 0.000180 || Feature6 | 0.450 | 0.480 | -0.030 | 0.000900 | 0.10 | 0.000090 || Feature7 | 0.150 | 0.200 | -0.050 | 0.002500 | 0.10 | 0.000250 |```总和 = 0.000168 + 0.000184 + 0.000135 + 0.000303 + 0.000180 + 0.000090 + 0.000250 = 0.001310Distance = √0.001310 = 0.0362最后使用冒泡排序法找出距离最近的Top-5:
if (Distance < DistArray[4]) { if (Distance < DistArray[0]) { DistArray[4] = DistArray[3]; LabelArray[4] = LabelArray[3]; DistArray[3] = DistArray[2]; LabelArray[3] = LabelArray[2]; DistArray[2] = DistArray[1]; LabelArray[2] = LabelArray[1]; DistArray[1] = DistArray[0]; LabelArray[1] = LabelArray[0]; DistArray[0] = Distance; LabelArray[0] = HistLabel; } else if (Distance < DistArray[1]) { DistArray[4] = DistArray[3]; LabelArray[4] = LabelArray[3]; DistArray[3] = DistArray[2]; LabelArray[3] = LabelArray[2]; DistArray[2] = DistArray[1]; LabelArray[2] = LabelArray[1]; DistArray[1] = Distance; LabelArray[1] = HistLabel; } else if (Distance < DistArray[2]) { DistArray[4] = DistArray[3]; LabelArray[4] = LabelArray[3]; DistArray[3] = DistArray[2]; LabelArray[3] = LabelArray[2]; DistArray[2] = Distance; LabelArray[2] = HistLabel; } else if (Distance < DistArray[3]) { DistArray[4] = DistArray[3]; LabelArray[4] = LabelArray[3]; DistArray[3] = Distance; LabelArray[3] = HistLabel; } else { DistArray[4] = Distance; LabelArray[4] = HistLabel; } ValidSamples = ValidSamples + 1;}结果:
最终Top-5结果:DistArray = [0.8, 1.0, 1.2, 1.5, 1.7]LabelArray = [1, 1, -1, 1, 1] ↓ ↓ ↓ ↓ ↓ 看涨 看涨 看跌 看涨 看涨Step 4: 加权投票预测
基于Top-5邻居的标签,使用距离倒数加权投票,得到预测结果。
计算公式
SumLabel = 0; SumWeight = 0; for j = 0 to 4 { if (DistArray[j] < 999999 && DistArray[j] > 0) { TempWeight = 1.0 / (DistArray[j] + 0.0001); SumLabel = SumLabel + LabelArray[j] * TempWeight; SumWeight = SumWeight + TempWeight; }}WeightedAvg = SumLabel / SumWeight;距离0.03 → 权重 1/0.03 ≈ 33.3 ⭐⭐⭐⭐⭐ (非常相似)
距离0.08 → 权重 1/0.08 = 12.5 ⭐⭐⭐ (一般相似)
距离0.20 → 权重 1/0.20 = 5.0 ⭐ (不太相似)
完整计算结果
| 排名 | 距离 | 标签 | 权重计算 | 权重值 | 标签×权重 ||------|------|------|----------|--------|----------|| 1 | 0.0362 | +1 | 1/(0.0362+0.0001) | 27.55 | +27.55 || 2 | 0.0520 | +1 | 1/(0.0520+0.0001) | 19.19 | +19.19 || 3 | 0.0680 | -1 | 1/(0.0680+0.0001) | 14.69 | **-14.69** || 4 | 0.0790 | +1 | 1/(0.0790+0.0001) | 12.64 | +12.64 || 5 | 0.0850 | +1 | 1/(0.0850+0.0001) | 11.76 | +11.76 |```SumLabel = 27.55 + 19.19 - 14.69 + 12.64 + 11.76 = 56.45SumWeight = 27.55 + 19.19 + 14.69 + 12.64 + 11.76 = 85.83WeightedAvg = 56.45 / 85.83 = 0.658转换为交易信号
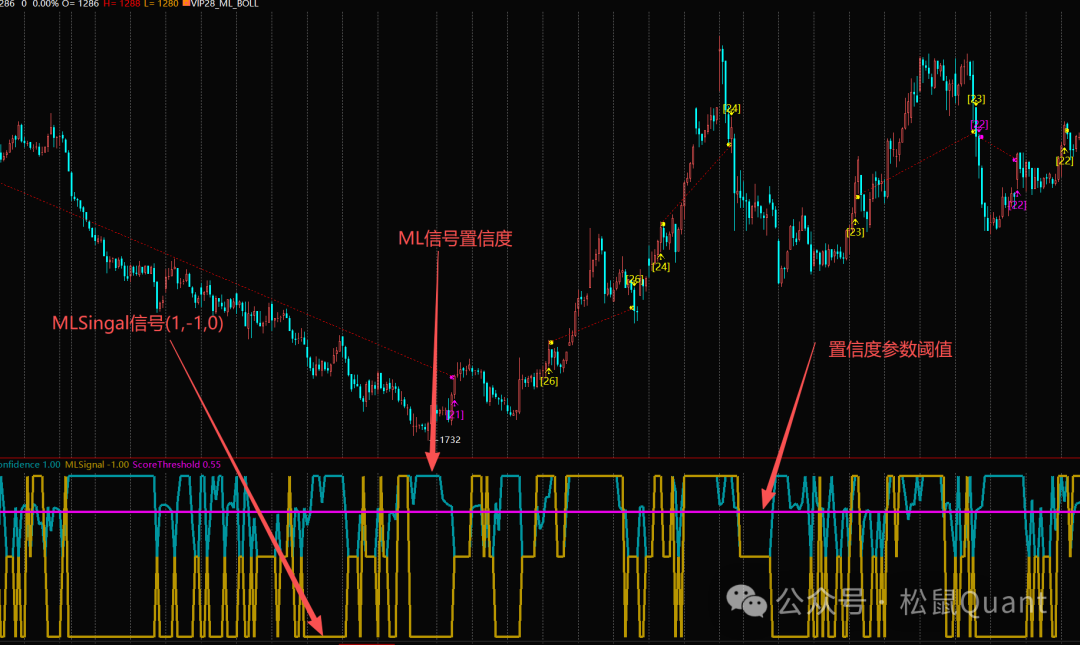
WeightedAvg = 0.658;if (WeightedAvg > 0.3) { MLSignal = 1; MLConfidence = Min(WeightedAvg, 1.0); } else if (WeightedAvg < -0.3) { MLSignal = -1; MLConfidence = Min(Abs(WeightedAvg), 1.0); } else { MLSignal = 0; MLConfidence = 0;}最终我们得到两个变量值,MLSignal和MLConfidence。
MLConfidence是信号的置信度,大于置信度时才有效。
示例结果:
WeightedAvg = 0.658 > 0.3→ MLSignal = 1 (看涨)→ MLConfidence = 0.658 (65.8%置信度)剩余的Step 5 6 7是简单条件组合与出场模块,就不再赘述。
💡 关键要点总结
VIP28_ML_KNN策略采用**在线学习(Online Learning)**模式,与传统机器学习的离线训练方式完全不同。
```工作流程:1. 收集历史数据2. 训练模型并保存参数3. 加载模型进行预测4. 定期重新训练更新模型``````每根K线实时执行:1. 自动使用最近500根K线作为训练集2. 计算当前K线特征与历史样本的距离3. 找到距离最近的5个邻居进行投票预测4. 滚动窗口自动更新,无需人工干预```### 为什么不需要?**传统监督学习(如神经网络)**```历史数据划分:├── 训练集 (70%) → 训练模型参数├── 验证集 (15%) → 调整超参数,防止过拟合└── 测试集 (15%) → 评估泛化能力```**需要划分的原因**: 神经网络需要训练参数,必须避免过拟合**KNN在线学习(当前策略)**```每根K线:└── 滚动窗口500根 → 直接作为"样本库" └── 实时查找K个最近邻 → 投票预测```**不需要划分的原因**:- ✅ **惰性学习**: KNN不训练参数,只存储样本- ✅ **实时预测**: 每次都重新计算距离,没有"记忆"- ✅ **滚动更新**: 窗口自动前移,天然避免未来函数- ✅ **非参数模型**: 没有需要"训练"的权重参数虽然VIP28_ML_KNN不需要划分训练集/验证集,但**必须验证预测有效性**。以下是完整的验证方法:
1.回测验证(基础)
```样本内(In-Sample): 2020-2022 → 70%数据参数优化样本外(Out-of-Sample): 2023-2024 → 30%数据最终验证```// 最优参数K_Neighbors = 5TrainingBars = 500ScoreThreshold = 0.65// 稳定性测试:参数±10%K_Neighbors: [4, 5, 6] // ±1TrainingBars: [450, 500, 550] // ±50ScoreThreshold: [0.60, 0.65, 0.70] // ±0.05VIP28里的K值与TrainingBars并不参与优化,所有品种均使用统一的K值与TrainingBars。当然,你可以去优化验证这组参数,但是要注意以下几点:
```K=3: 过度拟合风险,信号波动大K=5: 当前设置(推荐)K=7: 可能过于平滑,信号延迟K=10: 信号严重延迟,反应迟钝``````TrainingBars=300: 样本不足,泛化能力差TrainingBars=500: 当前设置(平衡)TrainingBars=1000: 计算量大,可能包含过时样本个人认为,优化K值与TrainingBars非常容易过拟合,请慎用。
3.特征重要性验证
测试各特征对预测的贡献度:```移除Feature1(趋势)→ 观察收益变化移除Feature2(动量)→ 观察收益变化移除Feature3(波动)→ 观察收益变化移除Feature4(成交量)→ 观察收益变化移除Feature5(BOLL位置)→ 观察收益变化移除Feature6(BOLL收缩)→ 观察收益变化移除Feature7(反转信号)→ 观察收益变化```观察某个移除特征对收益及回撤的影响:
1.如果移除某个特征,收益下降回撤上升,则这个特征有效。
2.移除特征后收益无明显变化或者正向增加,则这个特征是冗余的。
关于回测速度与运行速度
我开始也很担心Tbquant里每根K线都重新训练会严重拖慢速度,然而TBquant非常快,感官上无明显拖慢。小伙伴们拿到完整源码和工作区后感受一下。
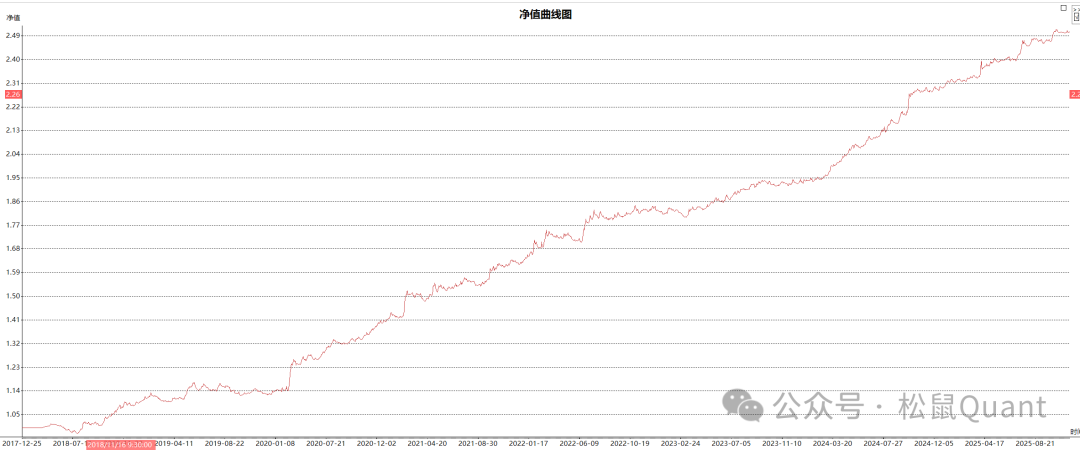
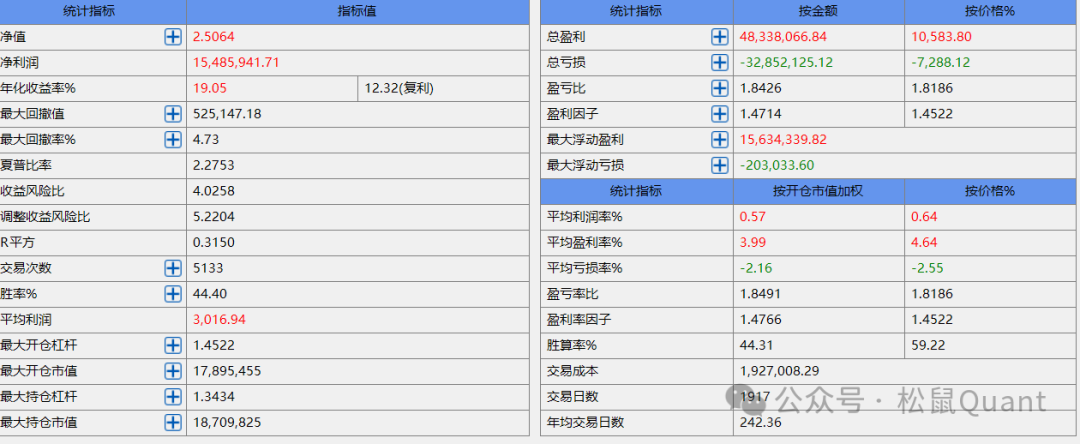
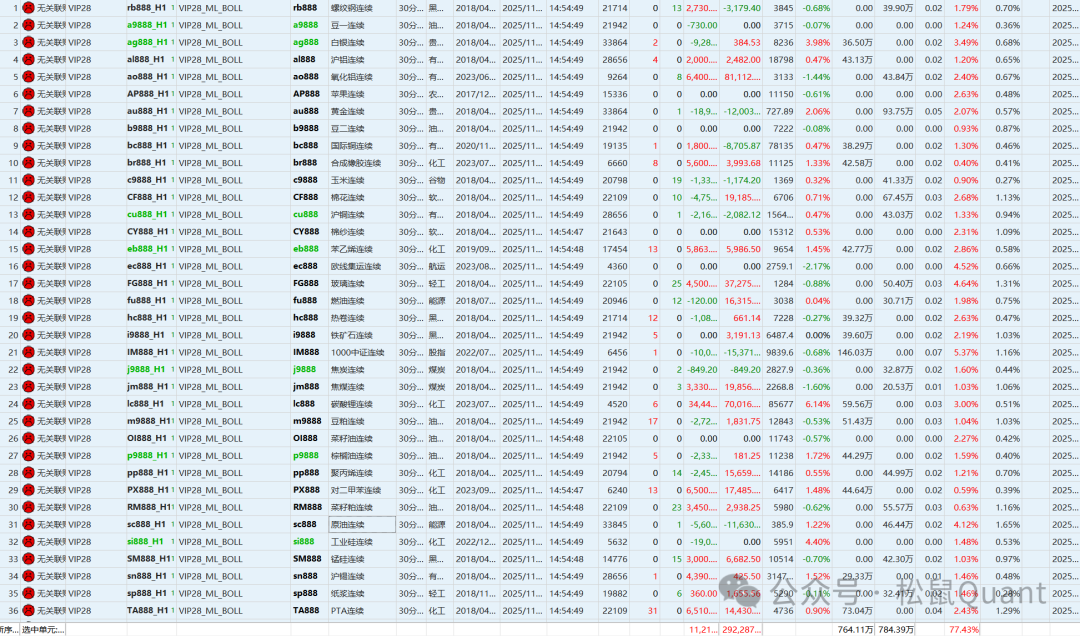
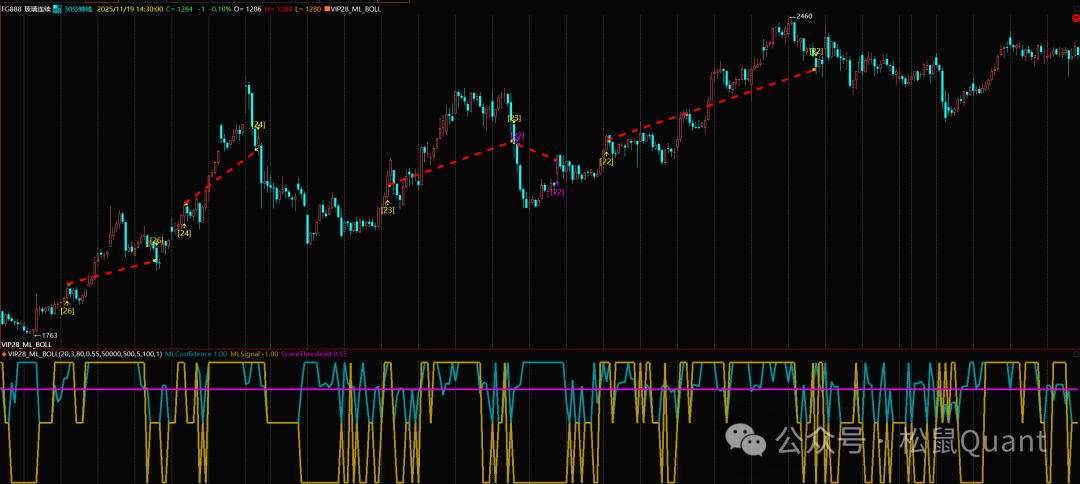
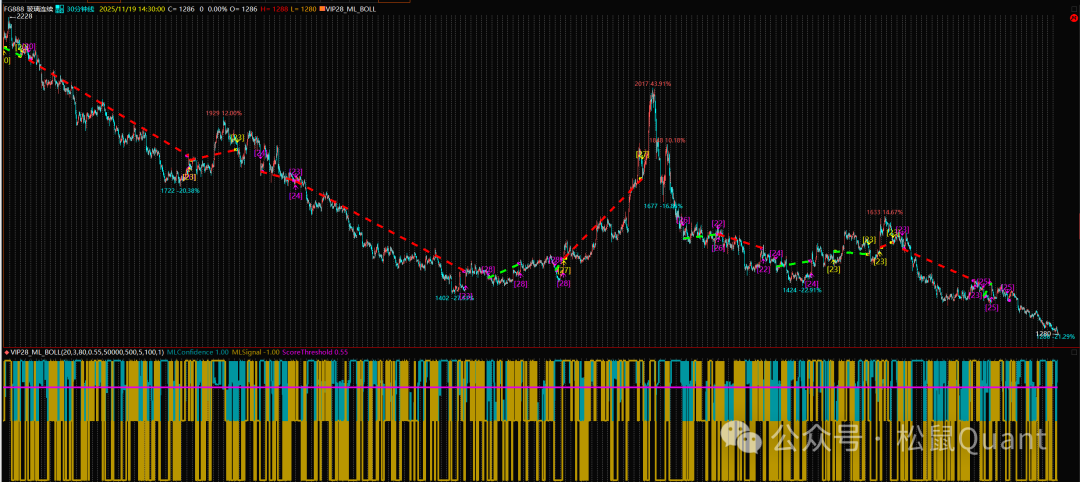
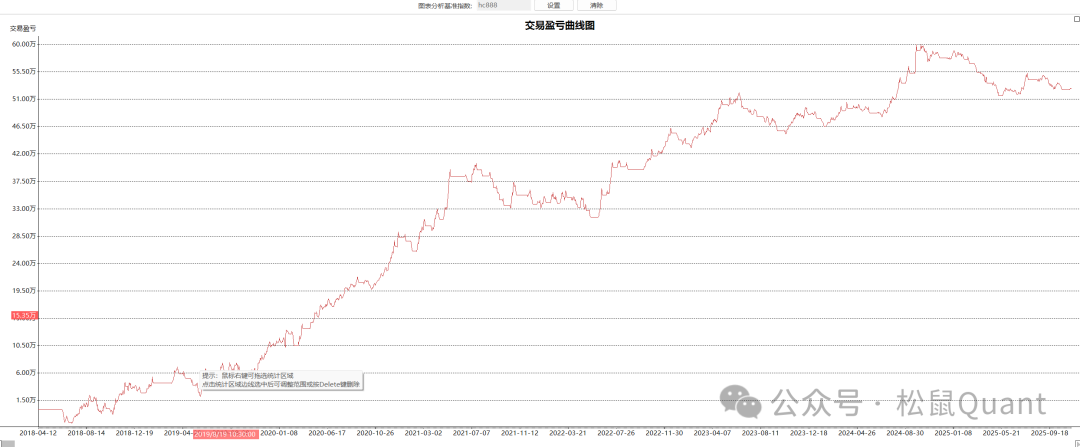
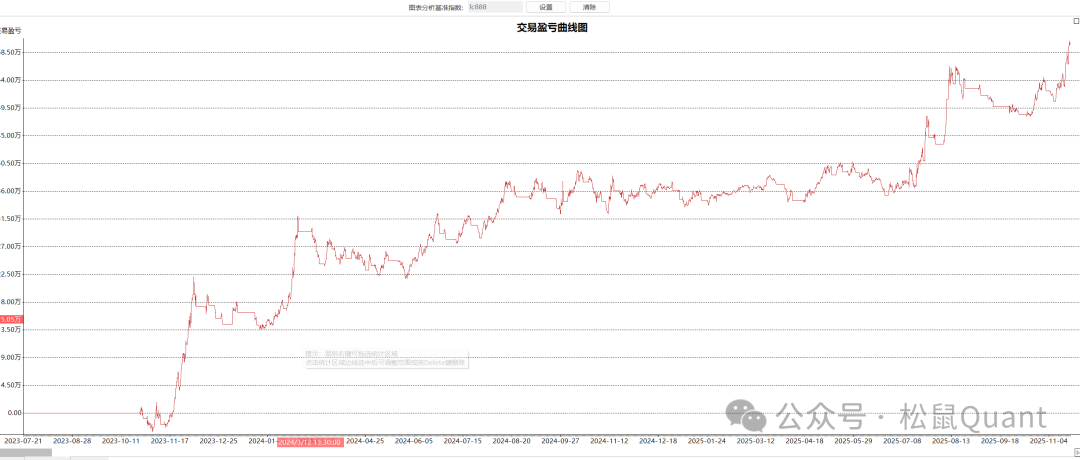
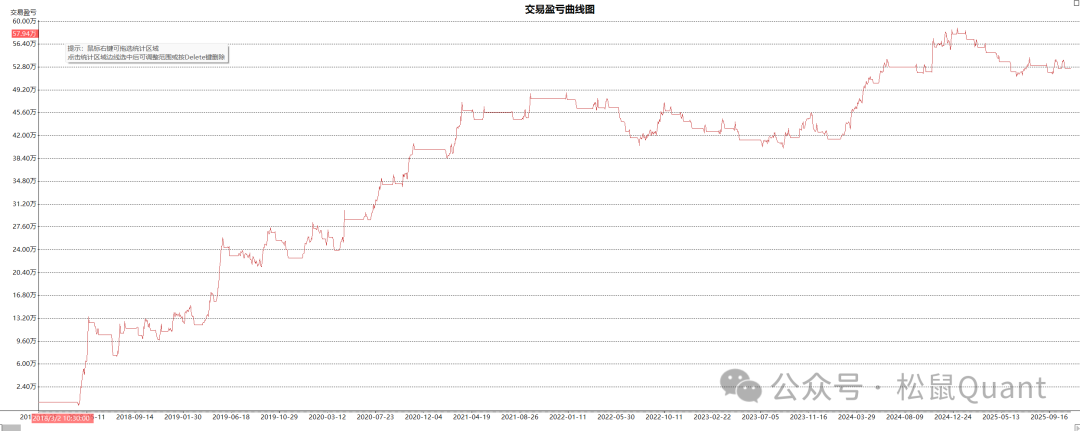
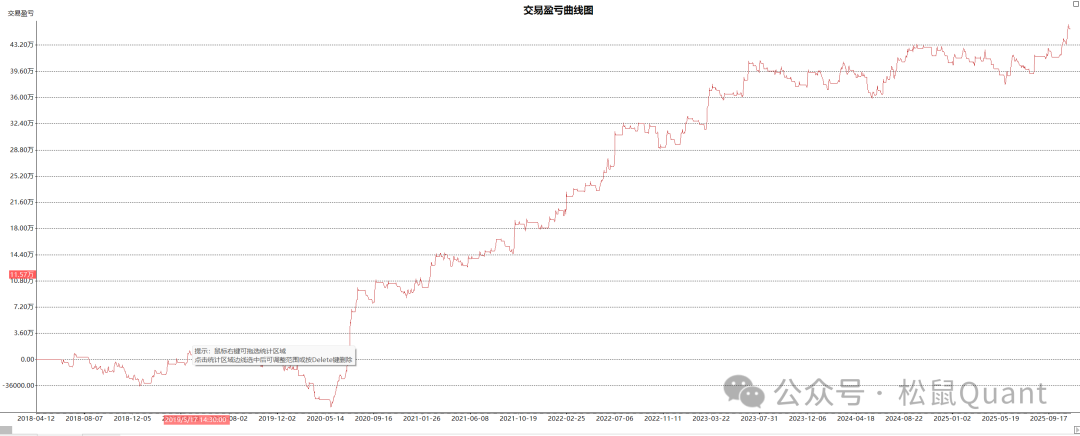
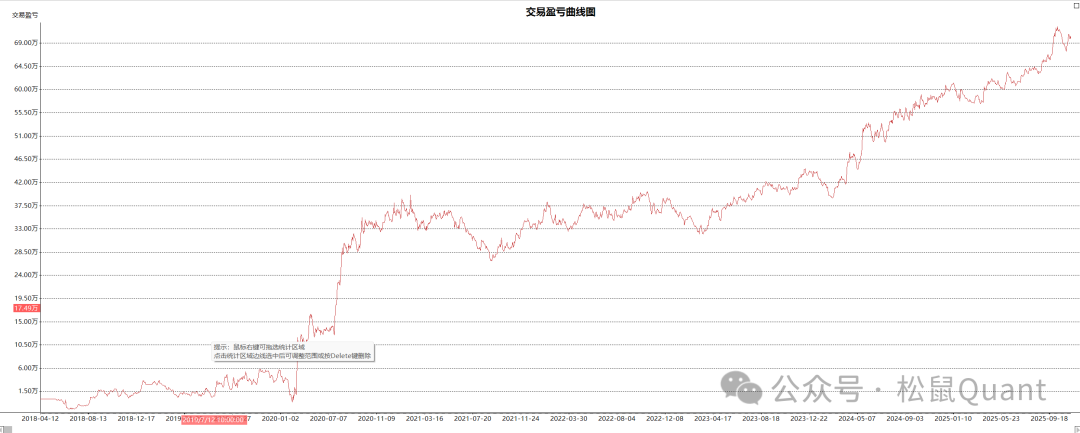
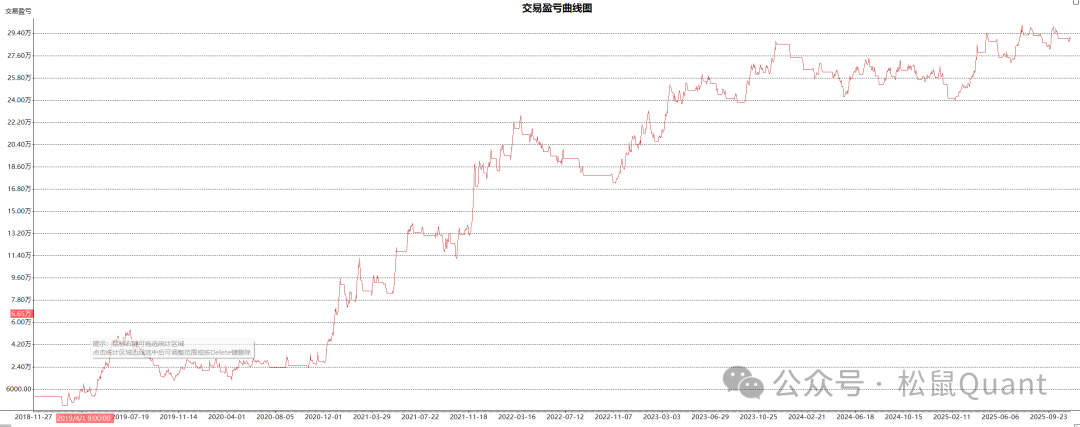
Tbquant回测报告
HC
LC
EC
AP
OI
ag
sp
总结
这是一次非常好的尝试,但不是最终的实盘策略,因为特征是常见的传统技术指标。初衷是抛砖引玉,小伙伴可以用这个模板平替里面的特征指标开发自己的机器学习多因子策略,使用Tbquant可以快速回测和验证。有几点经验分享:
1.特征不是越多越好,最好控制在10个以内。
2.充分验证特征的有效性,减少无用负收益的冗余特征。
3.慎用K值和TrainingBars的优化。
4.一定要做样本内外验证策略的有效性。
策略里有完整的代码注释,可以细细阅读:
源码包已经上传到2025俱乐部后台登录后下载:
微 信|小松鼠-松鼠Quant
微信号|viquant01